Previous work with Cyber-physical Systems
Arbitration is inevitable in any embedded system where multiple applications have to be serviced using shared computational and communication resources. Our research investigations pertain to the analysis and synthesis of Arbitrated Network Control Systems (ANCS) that are capable of obtaining high control performance with limited consumption of resources. Main features of the ANCS include (i) hierarchy and (ii) multi-modality, both of which are necessary components in the design of a DES where advanced controllers need to be implemented. An overview of the ANCS can be found here. Highlights of recent results are listed below.
Shared Decision-Making in the presence of varying relative degree
A shared architecture that has been recently developed is a combination of human pilot based decision making and an adaptive control based autopilot design. We propose the use of human pilot based on concepts of Capacity for Maneuver (CfM) and Graceful Command Degradation (GCD), both of which originate in Cognitive Sciences. Together, they provide guidelines for a system to be resilient, which corresponds to the system’s readiness to respond to unforeseen events. The proposed design incorporates elements from adaptive control theory under the control of human pilot. The shared control architecture is shown to be capable of achieving maximum CfM while allowing minimal GCD, as well as satisfactory command following post-anomaly, resulting in resilient flight capabilities. The proposed controller is analyzed in a simulation study of a nonlinear F-16 aircraft under actuator anomalies. It is shown through numerical studies that under suitable inputs from the pilot, the shared controller is able to deliver a resilient flight.
Shared Decision-Making in the presence of varying relative degree

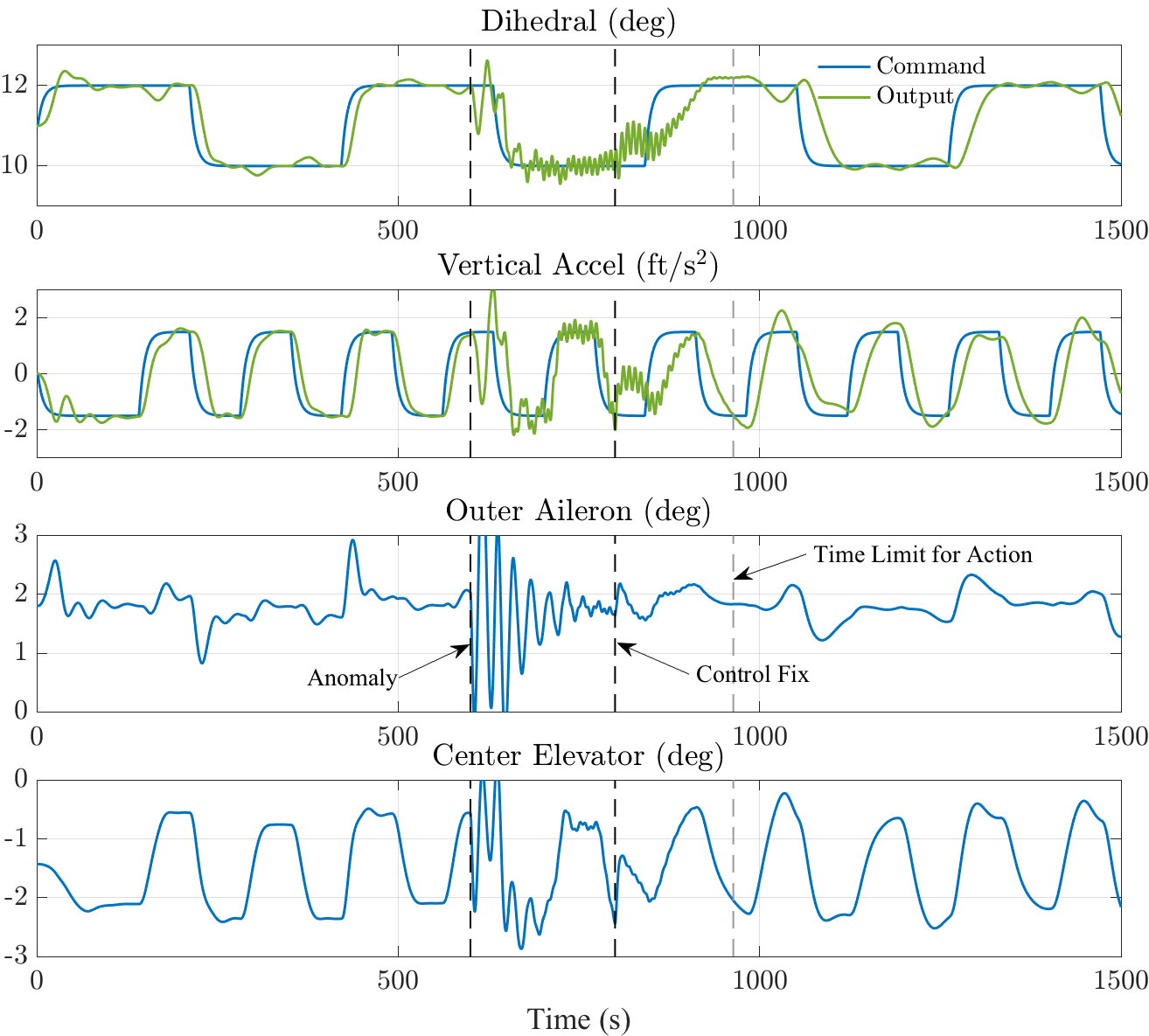
The shared control framework is applied to the anomaly response problem for a very flexible aircraft (VFA) model when the net order of the system changes due to to an anomaly. An autopilot based on model reference adaptive control (MRAC) with output feedback and closed-loop reference models (CRM) compensates for uncertainties in both the vehicle and actuator dynamics online. We consider an anomaly in the longitudinal dynamics of the HALE VFA, in which the actuator dynamics change from first-order to second-order. A passive (fully autonomous) anomaly response results in loss of stability and eventual structural failure of the vehicle. A complete transfer to manual control, on the other hand, may result in loss of control as remote human pilots are unfamiliar with the anomalous dynamics and are not able to sense the anomalous open-loop dynamics of the vehicle through typical vestibular pathways. A shared response, in which the human operator detects and isolates the anomaly, and intervenes to change the adaptive controller, allows for the recovery of the nominal command tracking performance in the presence of anomalous and uncertain actuator dynamics.
Cyber Attack Mitigation
The goal of this work is to develop a defense methodology for a cyber-physical system by which an attempted stealthy cyber-attack is detected in near real time. This work considers the effects of a type of stealthy attack on a class of cyber-physical systems that can be modeled as linear time-invariant systems. The effects of this attack are studied from both the perspective of the attacker as well as the defender. A previously developed method for conducting stealthy attacks is introduced and analyzed. Successful implementation of this attack is shown to require the attacker to attain perfect model knowledge in order for the attack to be stealthy. A method is then proposed in which the defender attempts to feed the attacker a slightly falsified model, baiting the attacker with data that will make an attack detectable. It is then shown that the defender can not only detect this faulty attack, but use observations of the detection signal to regain more accurate state estimates, mitigating the effect of the attack.
Hierarchical ANCS
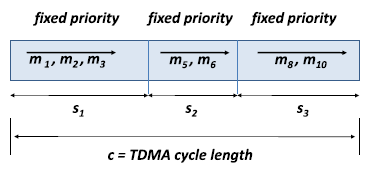
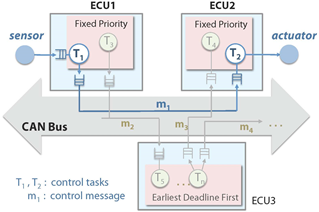
A hierarchical scheduling policy consists of several levels. At each level of the hierarchical scheduler runs a distinct scheduler. For example a hierarchical TDMA/FP scheduler has a TDMA scheduler at its top-level and a fixed priority scheduler at the second level, see Figure 1. In [2], it is shown how the parameters of hierarchical schedules on the communication bus can be optimally chosen and made to satisfy multiple control performance metrics using a schedulability analysis carried out using a Real-time Calculus framework.
In general, a DES consists of several components including sensors, actuators, ECUs and buses, a shared communication medium. As only one entity can send a message over a bus at one time, in a control application, the underlying ANCS needs to arbitrate the scheduling of messages sent by one plant to another. Together with the management of this information as well as that stemming from the underlying physical plants, the ANCS can be used to ensure high performance. In [3], we consider control of plants using a DES with a hierarchical schedule with uncertainties that may be present either in the plant or in the network. An adaptive controller is proposed to accommodate the effect of uncertainties. It is shown that this adaptive controller can accommodate the uncertainties, stabilize the system, make use of the structure of the hierarchical scheduler in its design, and result in improved performance compared to non-adaptive NCS.
Multi-Modal ANCS
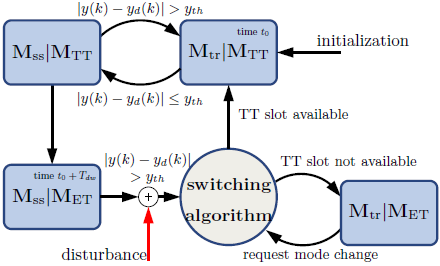
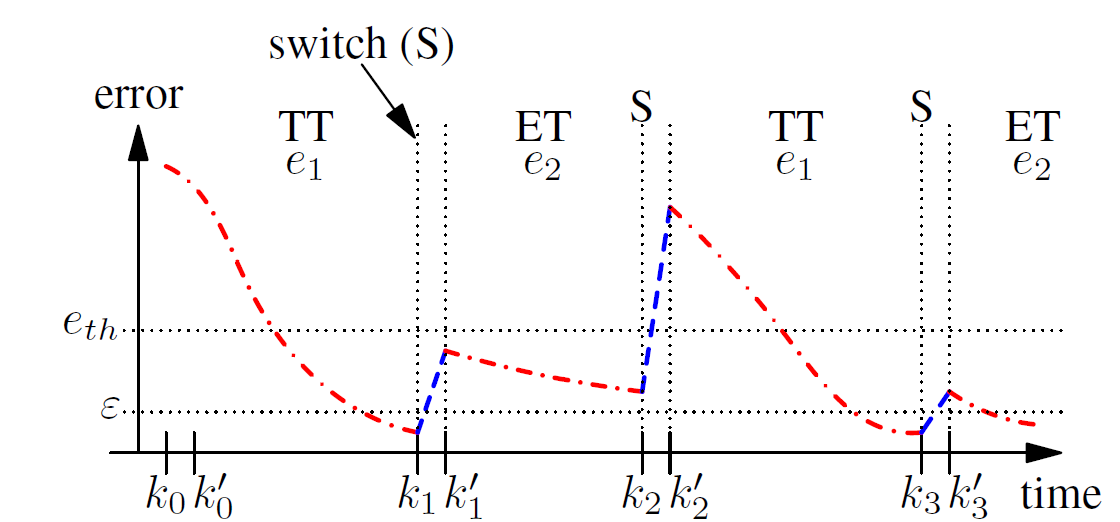
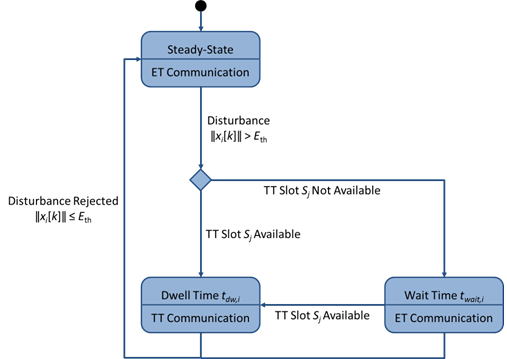
Often, a physical plant to be controlled has inherently different levels of operation called modes (denoted as Mss and Mtr, see Figure 1). The corresponding DES, by virtue of the distinct properties of the constituent protocols may have different modes as well. In addition, any resident non-control applications that need to be serviced by the DES may have their modes as well. This research is focused on a cyber-physical architecture with an ANCS with multiple processing units that communicate via a combination of time-triggered (MTT) and event-triggered (MET) modes and implement multiple control applications. Associated with each of these communication protocols are different set of advantages and disadvantages. The assignment of time-triggered (TT) slots to all control-related signals has the advantage of high quality of control (QoC) due to the possibility of reduced or zero delays, but leads to poor utilization of the communication bandwidth, high cost, overall inflexibility, and infeasibility as the number of control applications increase. On the other hand, event-triggered (ET) schedules often result in poor control performance due to the unpredictable temporal behavior of control messages and the related large delays which occurs due to the lack of availability of the bus. These imply that a hybrid protocol that suitably switches between these two schedules offers the possibility of exploiting their combined advantages of high QoC, efficient resource utilization, and low cost. A control application may have two modes, a transient one caused by external disturbances, and a steady-state one, with more stringent temporal constraints in the first case (see Figure 2). Given the differing properties of the constituent protocols and the distinct modes of a control application, we have developed a co-design of the control and protocol components is proposed that realizes their combined advantages. In particular, a switching controller is designed whose switches are aligned with those in the protocol. An adaptive component is added to the controller so as to accommodate uncertainties in the application as well as unforeseen changes in the protocol. The resulting adaptive switching controller is shown, using a FlexRay-based case study, to result in improved performance while requiring less time-triggered slots compared to non-adaptive co-designs. We use FlexRay as the hybrid protocol as it is the de-facto standard in automotive systems. Stability proofs and schedulability analysis have been derived.
Our next set of steps consists of the development of formal methods that combine control in engineering and real-time systems in computer science, and validation in an automotive system which is a typical example of a distributed embedded system.
Parallelized Model Predictive Control for Distributed Networked Systems
Model predictive control (MPC) has been used in many industrial applications because of its ability to produce optimal performance while accommodating constraints. However, its application on plants with fast time constants is difficult because of its computationally expensive algorithm. In this research, we propose a parallelized MPC that makes use of the structure of the computations and the matrices in the MPC. We show that the computational time of MPC with prediction horizon N can be reduced to O(log(N)) using parallel computing, which is significantly less than that with other available algorithms with similar accuracy.
Delay based Co-design in ANCS
The domain of networked control systems (NCS) has traditionally been concerned with modeling and designing distributed controllers in the presence of control message loss, varying delay and jitter. Here, the characteristics of the network are assumed to be given and the focus has largely been on the controller. In several cyber physical systems, it is possible to not only design distributed controllers, but also design both the scheduling parameters of the resident processors as well as those for the communication buses. We refer to such systems as arbitrated networked control systems (ANCS), where the parameters of the arbitration policies in the network are co-designed with the controller. Analytical methods from real-time calculus are used to design the former, and delay aware design procedures are used to determine the controller. A case study was performed on the co-design of platform and control of three quadrotors with delays. More details can be found in [1].
We investigated co-design of control and platform in the presence of dropped signals in [2]. In a cyber-physical system, due to increasing complexities such as the simultaneous control of several applications, limited resources, and complex platform architectures, some of the signals transmitted may often be dropped. We address the challenges that arise both from the control design and the platform design point of view. A dynamic model is proposed that accommodates these drops, and a suitable switching control design is proposed. A Multiple Lyapunov functions based approach is used to guarantee the stability of the system with the switching controller. We then present a method for optimizing the amount of platform resource required to ensure stability of the control systems via a buffer control mechanism that exploits the ability to drop signals of the control system and an associated analysis of the drop bound. The results are demonstrated using a case study of a co-designed lane keeping control system in the presence of dropped signals.
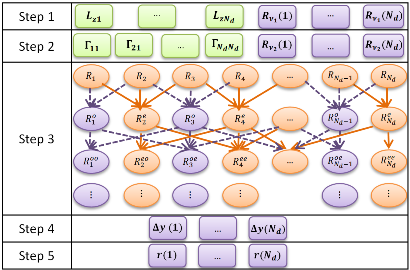
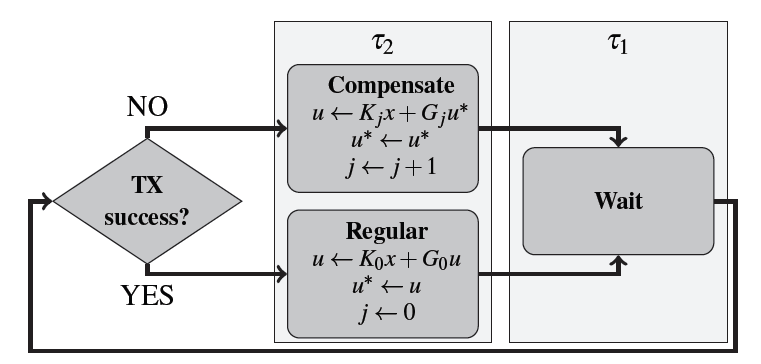
In [3], we exploited robustness of the controller and proposed a novel implementation approach to achieve a tighter design to answer the following questions: (i) given a distributed architecture, how to characterize and formally verify the bound on deadline misses, (ii) given such a bound, how to design a controller such that desired stability and Quality of Control (QoC) requirements are met. We addressed (i) by modeling a distributed embedded architecture as a network of Event Count Automata (ECA), and subsequently introducing and formally verifying a property formulation with reduced complexity. Question (ii) was addressed by introducing a novel fault-tolerant control strategy which adjusts the control input at runtime based on the occurrence of fault or drop. Using the proposed fault-tolerant strategy QoC under faulty communication improved significantly.
General Timing Analysis and Schedulability of Multiple Applications with Mixed Priority
Hybrid communication protocols such as FlexRay are often used in DES. We propose a co-design that uses information from closed-loop responses to determine an efficient resource utilization for control systems under hybrid communication protocols.
- Used multi-mode control structure
- Analyzed systems with non-monotonic behavior
- Leads to a less conservative schedulability analysis.
- Our approach: 3 slots, Monotonic upper-bound: 5 slots
- Reduced number of TT slots compared to those based on monotonic upper-bound
Security
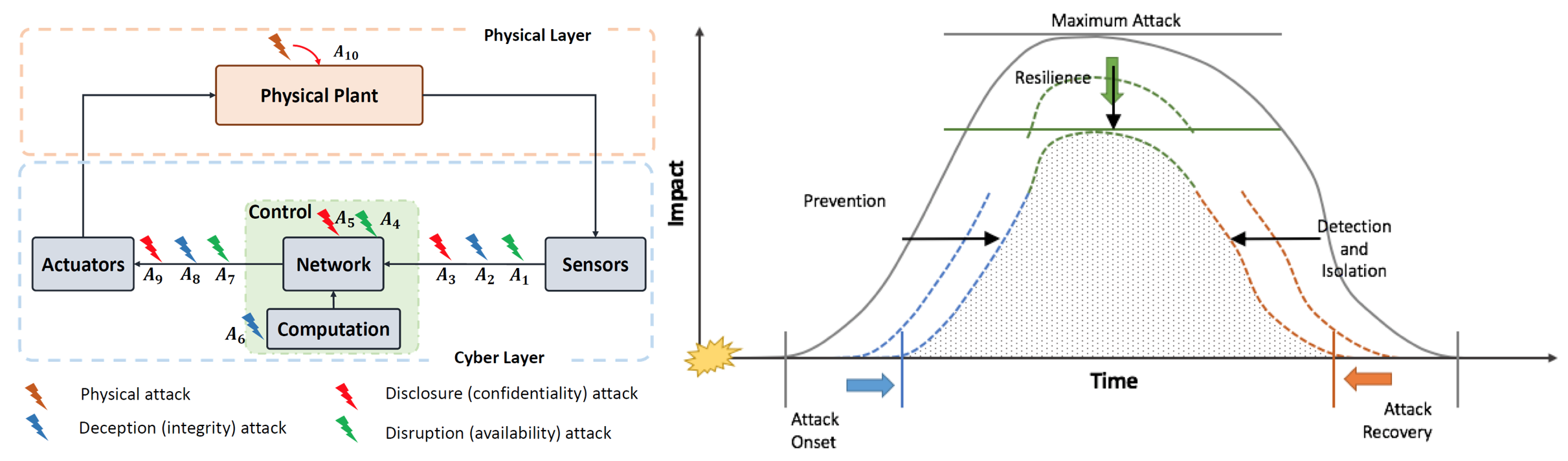
The comprehensive integration of instrumentation, communication, and control into physical systems has led to the study of Cyber-Physical Systems (CPSs), a field that has garnered increased attention. A key concern that is ubiquitous in CPS is a need to ensure security in the face of cyber attacks. We have carried out a survey of systems and control methods that have been proposed for the security of CPS. We classify these methods into three categories based on the type of defense proposed against the cyberattacks: prevention, resilience, and detection & isolation. A unified threat assessment metric is proposed in order to evaluate how CPS security is achieved in each of these three cases. Also surveyed are the risk assessment tools and the effect of network topology on CPS security.
Machine Learning for Optimal Delay-assignment
Given the strong presence of communication networks and networked controllers in cloud-based cyber-physical Systems, there is a strong need to co-design communication and control. Of specific interest is the design of delays that often arise when communication occurs over shared resources. In order to ensure an optimal control design in the presence of such delays, not only is it useful to have a delay-aware controller but a method by which optimal assignment of delays can be imposed on the communication network links. A project in our lab concerns the design of a delay-aware feedback controller that judiciously accommodates the most recent state information and a machine learning (ML) based method for determining the optimal delay assignment. This ML method consists of an offline training of a neural network whose inputs are a set of selected delays and outputs are relevant performance-optimizing metrics. The resulting neural network is shown to be capable of learning the optimal delay assignment to the various links in the communication network and therefore yielding optimal performance. The proposed method is validated using a power system case study of an IEEE 68-bus, and shown to result in a notable performance improvement where in 88% of the cases a near-optimal performance can be realized.